Building an AI-Powered Stock Analyzer: When the Scraper Isn't the Hard Part
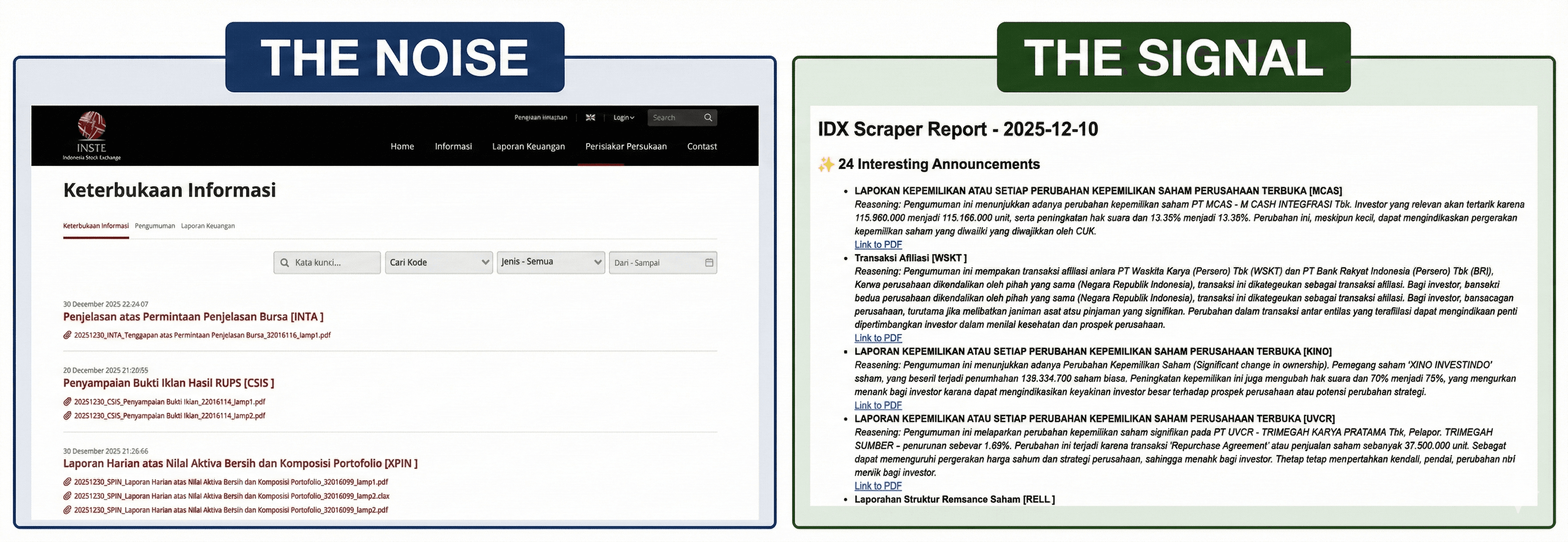
Hundreds of Indonesia Stock Exchange (IDX) announcements are released daily, but 90% of them are noise. I built an AI-powered system to cut through the noise and identify the "valuation catalysts" that could impact stock prices: acquisitions, rights issues, and backdoor listings.
Integrating AI into the system and building it took a single weekend. Fighting Cloudflare and production deployment took three weeks.
This project taught me the fundamental truth, the AI isn't the hard part—it's the infrastructure to make it work.
The Idea
I wanted a system that could:
- Filter interesting announcements from the IDX website.
- Download and analyze PDF attachments automatically.
- Use AI to filter signal from noise based on materiality.
- Send me the results back to me via email.
The Stack
- Data Collection: Puppeteer (headless browser automation)
- AI Analysis: Google Gemini 2.5 Flash Lite
- PDF Processing:
pdf-parse - Orchestration: Node.js + TypeScript
- Notifications: Nodemailer (email reports)
So, the flow is actually simple as you can see below

AI Integration
Modern AI has become a standard utility—just another API call in the stack. Gemini’s API took roughly 4 hours to integrate, including error handling. Here is the simplified code:
async function analyzeCombinedContent(
text: string,
scannedPdfBuffers: Buffer[],
title: string
): Promise<AnnouncementSentiment> {
const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY);
const model = genAI.getGenerativeModel({ model: 'gemini-2.5-flash-lite' });
const prompt = `
Analyze this Indonesian stock exchange announcement.
Title: ${title}
Content: ${text}
Is this a material event that could impact stock price?
Consider: mergers, acquisitions, bankruptcy, regulatory issues.
Ignore: routine reports, dividend schedules, administrative updates.
Return JSON: { "isInteresting": boolean, "reasoning": string }
`;
const parts = [{ text: prompt }];
// Add scanned PDF images for OCR
for (const buffer of scannedPdfBuffers) {
parts.push({
inlineData: {
mimeType: 'application/pdf',
data: buffer.toString('base64'),
},
});
}
const result = await model.generateContent(parts);
const response = result.response.text();
return JSON.parse(response);
}
No complex ML pipelines, no training data, no GPU clusters. Just an API call.
The hard part wasn’t the AI. It was getting the data to feed it.
The Real Challenge: Getting the Data
The IDX website doesn't have a public API. The announcements live behind a JavaScript-heavy interface. My Puppeteer scraper worked like a charm on my local machine, but the moment it touched GCP cloud IP, everything broke.
The Investigation: Why Cloud Deployments Fail
I spent two weeks debugging. Here is why my local machine passed while the production server failed:
- IP Reputation: My home ISP has a "clean" residential reputation. AWS IPs are flagged as data centers immediately.
- Browser Fingerprinting: Headless browsers lack GPUs and specific fonts that real browsers have.
- TLS Fingerprinting: Cloudflare can detect the underlying library (Puppeteer/Axios) by how it initiates the secure connection.
The Realization: Software as a Problem-Solving Tool
After three weeks of fighting the infrastructure, I hit a crossroads. I realized that as engineers, we often get seduced by the "cool" problem—in this case, bypassing enterprise-grade security like Cloudflare—and lose sight of the original goal.
Software is ultimately just a tool to solve a human problem. My problem was simple: I want to find market catalysts without reading 500 PDFs.
If I spent another month building a distributed proxy network to bypass Cloudflare just to host this on a cloud VM, I would no longer be solving my problem—I would be building a scraping business. By keeping the tool local, I leverage my residential IP (the "natural" way to access the web) and keep the focus where it belongs: on the AI-driven analysis.
If you want to see how the "brain" and the "plumbing" connect, you can check out the source code below. It’s not a shiny cloud app—it’s a working tool that solves a problem for me. Hopefully, it can help you solve yours, or at least save you three weeks of fighting a battle you don't need to win.
Github Repository: github.com/Bryan375/idx-keterbukaan-informasi-scraper